
一. LSA
1. LSA原理
LSA(latent semantic analysis)潜在语义分析,也被称为 LSI(latent semantic index),是 Scott Deerwester, Susan T. Dumais 等人在 1990 年提出来的一种新的索引和检索方法。该方法和传统向量空间模型(vector space model)一样使用向量来表示词(terms)和文档(documents),并通过向量间的关系(如夹角)来判断词及文档间的关系;不同的是,LSA 将词和文档映射到潜在语义空间,从而去除了原始向量空间中的一些“噪音”,提高了信息检索的精确度。
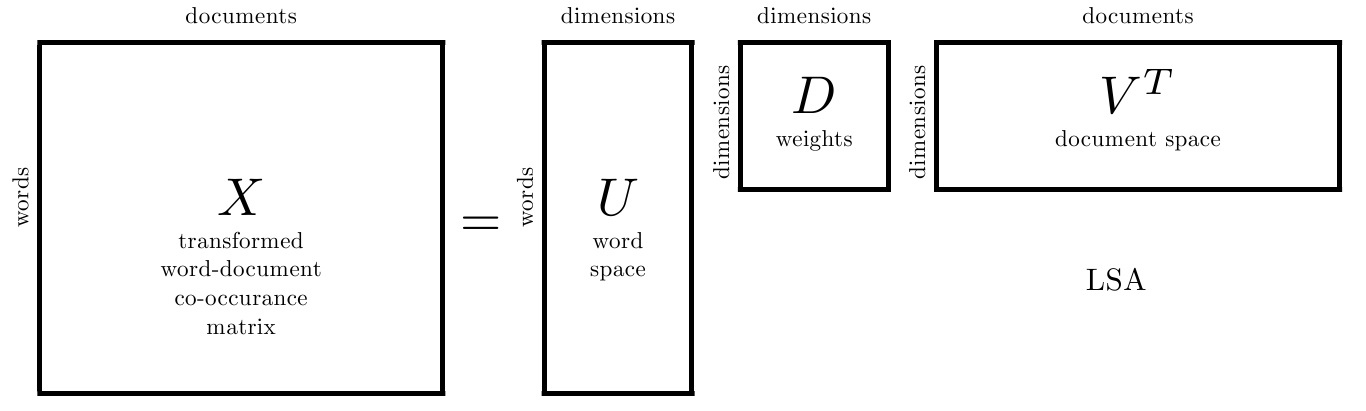
引用吴军老师在 “矩阵计算与文本处理中的分类问题” 中的总结:
三个矩阵有非常清楚的物理含义。第一个矩阵 U 中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。最后一个矩阵 V 中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵 D 则表示类词和文章类之间的相关性。因此,我们只要对关联矩阵 X 进行一次奇异值分解,我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。
传统向量空间模型使用精确的词匹配,即精确匹配用户输入的词与向量空间中存在的词,无法解决一词多义(polysemy)和一义多词(synonymy)的问题。实际上在搜索中,我们实际想要去比较的不是词,而是隐藏在词之后的意义和概念。
LSA 的核心思想是将词和文档映射到潜在语义空间,再比较其相似性。
举个简单的栗子,对一个 Term-Document 矩阵做SVD分解,并将左奇异向量和右奇异向量都取后2维(之前是3维的矩阵),投影到一个平面上(潜在语义空间),可以得到:
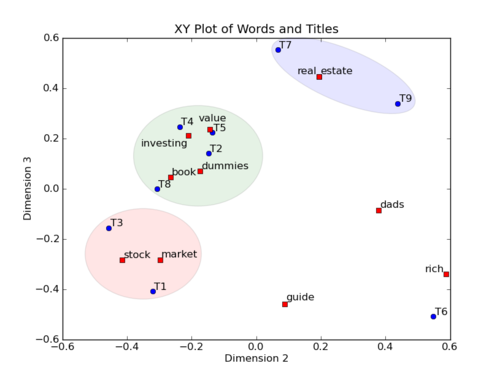
在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说 stock 和 market 可以放在一类,因为他们老是出现在一起,real 和 estate 可以放在一类,dads,guide 这种词就看起来有点孤立了,我们就不对他们进行合并了。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
2. LSA的优点
1)低维空间表示可以刻画同义词,同义词会对应着相同或相似的主题。
2)降维可去除部分噪声,是特征更鲁棒。
3)充分利用冗余数据。
4)无监督/完全自动化。
5)与语言无关。
3. LSA的缺点
1)LSA可以处理向量空间模型无法解决的一义多词(synonymy)问题,但不能解决
网友评论
