
Linux系统中文语言乱码,是很多小伙伴在开始接触Linux时经常遇到的问题,而且当我们将已在Wndows部署好的项目搬到Linux上运行时,Tomcat的输出日志中文全为乱码(在Windows上正常),看着非常心塞,那么我们应该怎么解决呢?
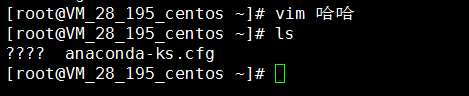
系统中文乱码

Tomcat输出日志中文乱码
系统环境
CentOS 7.0 64位
jdk-8u11-linux-x64.
apache-tomcat-8.5.16
解决步骤:
1.安装中文语言包
先查看系统是否有安装中文语言包
# locale -
