
手头现在有一份福布斯2016年全球上市企业2000强排行榜的数据,但原始数据并不规范,需要处理后才能进一步使用。
本文通过实例操作来介绍用pandas进行数据整理。
照例先说下我的运行环境,如下:
windows 7, 64位
python 3.5
pandas 0.19.2版本
在拿到原始数据后,我们先来看看数据的情况,并思考下我们需要什么样的数据结果。
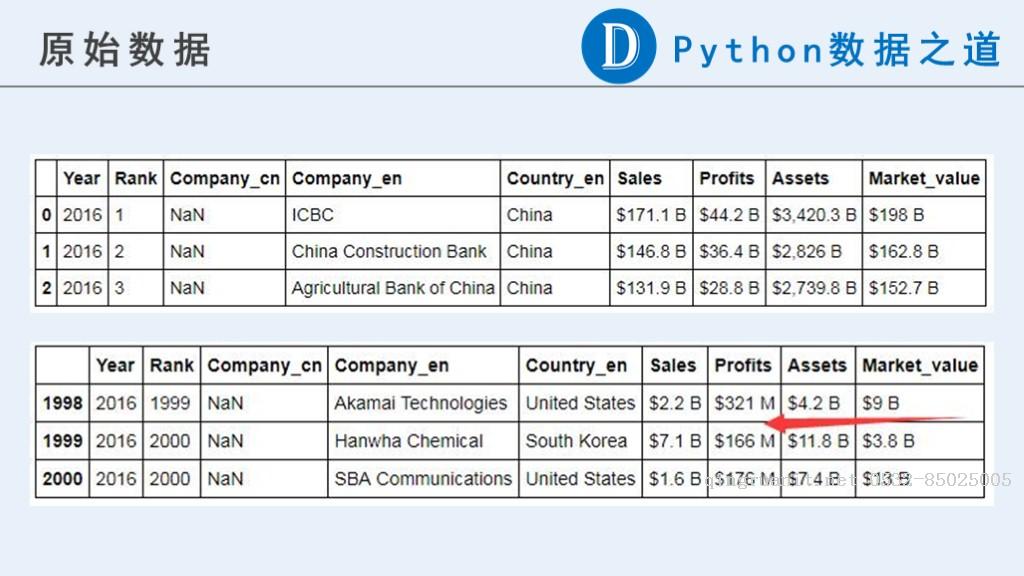
下面是原始数据:
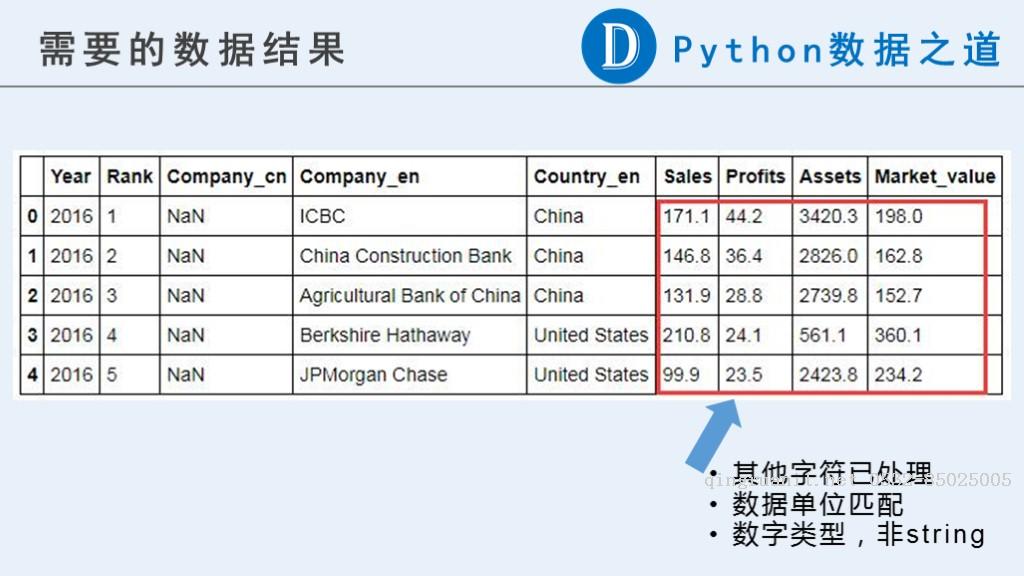
在本文中,我们需要以下的初步结果,以供以后继续使用。
可以看到,原始数据中,跟企业相关的数据中(“Sales”,“Profits”,“Assets”,“Market_value”),目前都是不是可以用来计算的数字类型。
原始内容中包含货币符号”$“,“-”,纯字母组成的字符串以及其他一些我们认为异常的信息。更重要的是,这些数据的单位并不一致。分别有以“B”(Billion,十亿)和“M”(Million,百万)表示的。在后续计算之前需要进行单位统一。
1 处理方法 Method-1
首先想到的处理思路就是将数据信息分别按十亿(’B’)和百万(‘M’)进行拆分,分别进行处理,最后在合并到一起。过程如下所示。
加载数据,并添加列的名称
import pandas as pd
df_2016 = pd.read_csv('data_2016.csv', encoding='gbk',header=None)# 更新列名df_2016.columns = ['Year', 'Rank', 'Company_cn','Company_en', 'Country_en', 'Sales', 'Profits', 'Assets', 'Market_value']
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)