
文章出处
文章出自:安卓进阶学习指南
作者:shixinzhang
完稿日期:2017.10.25
Collections 和 Arrays 是 JDK 为我们提供的常用工具类,方便我们操作集合和数组。
这次之所以总结这个,是因为在一次面试中被问到一个细节,回答地不太好,这里补一下吧。
由于两个都是工具类,我们就放在一起学习。
读完本文你将了解:
Collections
Collections 从名字就可以看出来,是对集合的操作,它提供了一系列内部类集合,主要为以下类型:
不可变集合
同步的集合
有类型检查的集合
空集合
只含一个元素的集合
还提供了一系列很有用的静态方法,主要包括以下功能:
排序
二分查找
反转
打乱
交换元素位置
复制
求出集合中最小/大值
我们先来看内部类的实现。
提供的多种内部类
1.不可变集合
有时候我们拿到一部分数据,这个数据不允许修改、删除,只允许读取,我们可以使用 Collections.unmodifiableXXX() 方法来实现。
Collections 提供了对以下集合的不可变支持:
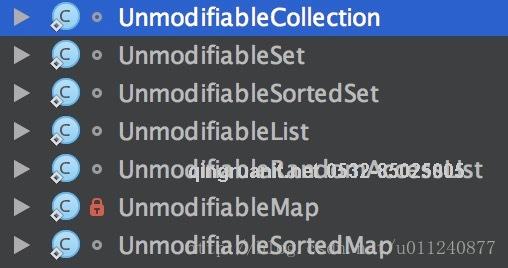
我们选几个看一下源码。
首先看下最大范围的 Collections.unmodifiableCollection(c) 方法,它可以返回一个容器的包装类,这个包装类的添加、替换、删除操作都会抛出异常 UnsupportedOperationException。
public static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c) { return new UnmodifiableCollection<>(c);
}//一个不可变的集合static class UnmodifiableCollection<E> implements Collection<E>, Serializable { private static final long serialVersionUID = 1820017752578914078L; final Collection<? extends E> c;
UnmodifiableCollection(Collection<? extends E> c) { if (c==null) throw new NullPointerException(); this.c = c;
} //普通查询操作都是支持的,没什么特别
public int size() {return c.size();} public boolean isEmpty() {return c.isEmpty();} public boolean contains(Object o) {return c.contains(o);} public Object[] toArray() {return c.toArray();} public <T> T[] toArray(T[] a) {return c.toArray(a);} public String toString() {return c.toString();} public Iterator<E> iterator() { return new Iterator<E>() { private final Iterator<? extends E> i = c.iterator(); public boolean hasNext() {return i.hasNext();} public E next() {return i.next();} public void remove() { //迭代器的 remove 也不支持
throw new UnsupportedOperationException();
} @Override
public void forEachRemaining(Consumer<? super E> action) { // Use backing collection version
i.forEachRemaining(action);
}
};
} //这里开始一系列修改操作就不支持了
public boolean add(E e) { throw new UnsupportedOperationException();
} public boolean remove(Object o) { throw new UnsupportedOperationException();
} public boolean containsAll(Collection<?> coll) { return c.containsAll(coll);
} public boolean addAll(Collection<? extends E> coll) { throw new UnsupportedOperationException();
} public boolean removeAll(Collection<?> coll) { throw new UnsupportedOperationException();
} public boolean retainAll(Collection<?> coll) { throw new UnsupportedOperationException();
} public void clear() { throw new UnsupportedOperationException();
} // Override default methods in Collection
@Override
public void forEach(Consumer<? super E> action) {
c.forEach(action);
} @Override
public boolean removeIf(Predicate<? super E> filter) { throw new UnsupportedOperationException();
}
}12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576剩下的也基本一样了,再看个 Collections.unmodifiableList() 吧:
public static <T> List<T> unmodifiableList(List<? extends T> list) { return (list instanceof RandomAccess ? new UnmodifiableRandomAccessList<>(list) : new UnmodifiableList<>(list));
}static class UnmodifiableList<E> extends UnmodifiableCollection<E>
implements List<E> { private static final long serialVersionUID = -283967356065247728L; final List<? extends E> list;
UnmodifiableList(List<? extends E> list) { super(list); this.list = list;
} public boolean equals(Object o) {return o == this || list.equals(o);} public int hashCode() {return list.hashCode();} public E get(int index) {return list.get(index);} public E set(int index, E element) { //不支持
throw new UnsupportedOperationException();
} public void add(int index, E element) { //不支持
throw new UnsupportedOperationException();
} public E remove(int index) {//不支持
throw new UnsupportedOperationException();
} public int indexOf(Object o) {return list.indexOf(o);} public int lastIndexOf(Object o) {return list.lastIndexOf(o);} public boolean addAll(int index, Collection<? extends E> c) { throw new UnsupportedOperationException();
} @Override
public void replaceAll(UnaryOperator<E> operator) { throw new UnsupportedOperationException();
} @Override
public void sort(Comparator<? super E> c) { throw new UnsupportedOperationException();
} public ListIterator<E> listIterator() {return listIterator(0);} public ListIterator<E> listIterator(final int index) { return new ListIterator<E>() { private final ListIterator<? extends E> i
= list.listIterator(index); public boolean hasNext() {return i.hasNext();} public E next() {return i.next();} public boolean hasPrevious() {return i.hasPrevious();} public E previous() {return i.previous();} public int nextIndex() {return i.nextIndex();} public int previousIndex() {return i.previousIndex();} public void remove() { throw new UnsupportedOperationException();
} public void set(E e) { throw new UnsupportedOperationException();
} public void add(E e) { throw new UnsupportedOperationException();
} @Override
public void forEachRemaining(Consumer<? super E> action) {
i.forEachRemaining(action);
}
};
} public List<E> subList(int fromIndex, int toIndex) { return new UnmodifiableList<>(list.subList(fromIndex, toIndex));
}
}123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778其他类型的不可变集合也基本是这样的,用一个包装器类,持有实际集合类的引用,只对外提供查询的方法,增删改的通通抛异常。
2.同步的集合
如果你需要将一个集合的所有操作都设置为线程安全的,Collections.synchronizedXXX() 是一种方法。
Collections 提供了对以下集合的同步化支持:
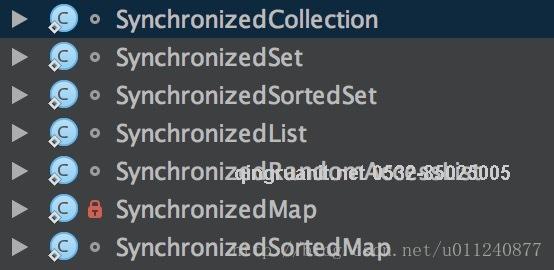
我们选几个典型的看看实现。
public static <T> Collection<T> synchronizedCollection(Collection<T> c) { return new SynchronizedCollection<>(c);
}//第二个参数是用于同步的对象static <T> Collection<T> synchronizedCollection(Collection<T> c, Object mutex) { return new SynchronizedCollection<>(c, mutex);
}static class SynchronizedCollection<E> implements Collection<E>, Serializable { private static final long serialVersionUID = 3053995032091335093L; final Collection<E> c; // 实际的集合
final Object mutex; // 同步的对象
SynchronizedCollection(Collection<E> c) { this.c = Objects.requireNonNull(c);
mutex = this;
}
SynchronizedCollection(Collection<E> c, Object mutex) { this.c = Objects.requireNonNull(c); this.mutex = Objects.requireNonNull(mutex);
} public int size() { synchronized (mutex) {return c.size();}
} public boolean isEmpty() { synchronized (mutex) {return c.isEmpty();}
} public boolean contains(Object o) { synchronized (mutex) {return c.contains(o);}
} public Object[] toArray() { synchronized (mutex) {return c.toArray();}
} public <T> T[] toArray(T[] a) { synchronized (mutex) {return c.toArray(a);}
} public Iterator<E> iterator() { return c.iterator(); // 迭代器没有进行同步操作,需要使用者自己同步
} public boolean add(E e) { synchronized (mutex) {return c.add(e);}
} public boolean remove(Object o) { synchronized (mutex) {return c.remove(o);}
} public boolean containsAll(Collection<?> coll) { synchronized (mutex) {return c.containsAll(coll);}
} public boolean addAll(Collection<? extends E> coll) { synchronized (mutex) {return c.addAll(coll);}
} public boolean removeAll(Collection<?> coll) { synchronized (mutex) {return c.removeAll(coll);}
} public boolean retainAll(Collection<?> coll) { synchronized (mutex) {return c.retainAll(coll);}
} public void clear() { synchronized (mutex) {c.clear();}
} public String toString() { synchronized (mutex) {return c.toString();}
} // Override default methods in Collection
@Override
public void forEach(Consumer<? super E> consumer) { synchronized (mutex) {c.forEach(consumer);}
} @Override
public boolean removeIf(Predicate<? super E> filter) { synchronized (mutex) {return c.removeIf(filter);}
} @Override
public Spliterator<E> spliterator() { return c.spliterator(); // Must be manually synched by user!
} @Override
public Stream<E> stream() { return c.stream(); // Must be manually synched by user!
} @Override
public Stream<E> parallelStream() { return c.parallelStream(); // Must be manually synched by user!
} private void writeObject(ObjectOutputStream s) throws IOException { synchronized (mutex) {s.defaultWriteObject();}
}
}1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586878889909192939495可以看到实现很简单,几乎在所有方法上都添加了 synchronized,这样得到的集合在并发环境中效率可是大打折扣。要是对准确率要求比性能高,可以用用。
不过需要注意的是,我们在使用 Collections.synchronizedCollection(c) 返回的迭代器时,需要手动对迭代器进行同步,比如这样:
Collection c = Collections.synchronizedCollection(myCollection); ...
synchronized (c) {
Iterator i = c.iterator(); // Must be in the synchronized block while (i.hasNext())
foo(i.next());
}1234567否则在迭代时有并发操作,可能会导致不确定性问题。
其他的同步集合也都类似,暴力的使用了 synchronized,没什么特别的,就不赘述了。
3.有类型检查的集合
日常开发中我们经常需要使用 Object 作为返回值,然后在具体的使用处强转成指定的类型,在这个强转的过程中,编译器无法检测出强转是否成功。
这时我们就可以使用 Collections.checkedXXX(c, type) 方法创建一个只保存某个类型数据的集合,在添加时会进行类型检查操作。
虽然使用泛型也可以实现在编译时检查,但在运行时,泛型擦除成 Object,最终还是需要强转。
Collections 提供了对以下集合的类型检查:
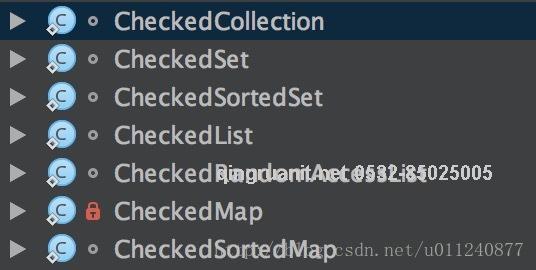
Collections.checkedCollection(c, type) 方法提供了操作所有集合的基本操作,我们直接看它如何实现的就好了:
public static <E> Collection<E> checkedCollection(Collection<E> c,
Class<E> type) { return new CheckedCollection<>(c, type);
}@SuppressWarnings("unchecked")static <T> T[] zeroLengthArray(Class<T> type) { return (T[]) Array.newInstance(type, 0);
}/**
* @serial include
*/static class CheckedCollection<E> implements Collection<E>, Serializable { private static final long serialVersionUID = 1578914078182001775L; final Collection<E> c; final Class<E> type; //目标类型
void typeCheck(Object o) { if (o != null && !type.isInstance(o)) //检查是否和目标类型一致
throw new ClassCastException(badElementMsg(o));
} private String badElementMsg(Object o) { return "Attempt to insert " + o.getClass() + " element into collection with element type " + type;
}
CheckedCollection(Collection<E> c, Class<E> type) { if (c==null || type == null) throw new NullPointerException(); this.c = c; this.type = type;
} public int size() { return c.size(); } public boolean isEmpty() { return c.isEmpty(); } public boolean contains(Object o) { return c.contains(o); } public Object[] toArray() { return c.toArray(); } public <T> T[] toArray(T[] a) { return c.toArray(a); } public String toString() { return c.toString(); } public boolean remove(Object o) { return c.remove(o); } public void clear() { c.clear(); } public boolean containsAll(Collection<?> coll) { return c.containsAll(coll);
} public boolean removeAll(Collection<?> coll) { return c.removeAll(coll);
} public boolean retainAll(Collection<?> coll) { return c.retainAll(coll);
} public Iterator<E> iterator() { // JDK-6363904 - unwrapped iterator could be typecast to
// ListIterator with unsafe set()
final Iterator<E> it = c.iterator(); return new Iterator<E>() { public boolean hasNext() { return it.hasNext(); } public E next() { return it.next(); } public void remove() { it.remove(); }}; // Android-note: Should we delegate to it for forEachRemaining ?
} public boolean add(E e) { //添加时调用了类型检查
typeCheck(e); return c.add(e);
} private E[] zeroLengthElementArray = null; // Lazily initialized
private E[] zeroLengthElementArray() { return zeroLengthElementArray != null ? zeroLengthElementArray :
(zeroLengthElementArray = zeroLengthArray(type));
} public boolean addAll(Collection<? extends E> coll) { //这个方法可以让我们避免并发时内容改变导致的问题
return c.addAll(checkedCopyOf(coll));
} @SuppressWarnings("unchecked") //检查集合中的每个元素的类型
Collection<E> checkedCopyOf(Collection<? extends E> coll) {
Object[] a = null; try {
E[] z = zeroLengthElementArray();
a = coll.toArray(z); // Defend against coll violating the toArray contract
if (a.getClass() != z.getClass())
a = Arrays.copyOf(a, a.length, z.getClass());
} catch (ArrayStoreException ignore) { // To get better and consistent diagnostics,
// we call typeCheck explicitly on each element.
// We call clone() to defend against coll retaining a
// reference to the returned array and storing a bad
// element into it after it has been type checked.
//
a = coll.toArray().clone(); for (Object o : a)
typeCheck(o);
} // A slight abuse of the type system, but safe here.
return (Collection<E>) Arrays.asList(a);
} // Override default methods in Collection
@Override
public void forEach(Consumer<? super E> action) {c.forEach(action);} @Override
public boolean removeIf(Predicate<? super E> filter) { return c.removeIf(filter);
} @Override
public Spliterator<E> spliterator() {return c.spliterator();} @Override
public Stream<E> stream() {return c.stream();} @Override
public Stream<E> parallelStream() {return c.parallelStream();}123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121可以看到,只是在 add(e) addAll() 时进行了类型检查而已,不符合目标类型就会抛出 ClassCastException 异常。
4.空集合
目前我还没想出什么时候需要创建一个空集合,看 Collections.emptyList() 的源码,创建的空列表除了内容为 0,还不支持添加操作,也就是永远就是个空的。
何必呢?不懂啊。
public static final <T> List<T> emptyList() { return (List<T>) EMPTY_LIST;
}/**
* @serial include
*/private static class EmptyList<E>
extends AbstractList<E>
implements RandomAccess, Serializable { private static final long serialVersionUID = 8842843931221139166L; public Iterator<E> iterator() { return emptyIterator();
} public ListIterator<E> listIterator() { return emptyListIterator();
} public int size() {return 0;} public boolean isEmpty() {return true;} public boolean contains(Object obj) {return false;} public boolean containsAll(Collection<?> c) { return c.isEmpty(); } public Object[] toArray() { return new Object[0]; } public <T> T[] toArray(T[] a) { if (a.length > 0)
a[0] = null; return a;
} public E get(int index) { throw new IndexOutOfBoundsException("Index: "+index);
} public boolean equals(Object o) { return (o instanceof List) && ((List<?>)o).isEmpty();
} public int hashCode() { return 1; }
@Override public boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter); return false;
} // Override default methods in Collection
@Override public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
}
@Override public Spliterator<E> spliterator() { return Spliterators.emptySpliterator(); }
@Override public void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
}
@Override public void sort(Comparator<? super E> c) {
} // Preserves singleton property
private Object readResolve() { return EMPTY_LIST;
}
}1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071725.只含一个元素的集合
这个很好理解,有时候第三方方法需要的参数是一个 Map,而我们只有一组 key-value 数据怎么办,可以使用 Collections.singletonMap(key, value) 创建一个 Map。
我们来看下它的源码:
public static <K,V> Map<K,V> singletonMap(K key, V value) { return new SingletonMap<>(key, value);
}private static class SingletonMap<K,V>
extends AbstractMap<K,V>
implements Serializable { private static final long serialVersionUID = -6979724477215052911L; private final K k; private final V v; //构造函数中将参数的 k-v 保存到唯一的 k 和 v 中
SingletonMap(K key, V value) {
k = key;
v = value;
} public int size() {return 1;} public boolean isEmpty() {return false;} public boolean containsKey(Object key) {return eq(key, k);} public boolean containsValue(Object value) {return eq(value, v);} public V get(Object key) {return (eq(key, k) ? v : null);} private transient Set<K> keySet = null; private transient Set<Map.Entry<K,V>> entrySet = null; private transient Collection<V> values = null; public Set<K> keySet() { if (keySet==null)
keySet = singleton(k); return keySet;
} public Set<Map.Entry<K,V>> entrySet() { if (entrySet==null)
entrySet = Collections.<Map.Entry<K,V>>singleton( new SimpleImmutableEntry<>(k, v)); return entrySet;
} public Collection<V> values() { if (values==null)
values = singleton(v); return values;
} // Override default methods in Map
@Override public V getOrDefault(Object key, V defaultValue) { return eq(key, k) ? v : defaultValue;
}
@Override public void forEach(BiConsumer<? super K, ? super V> action) {
action.accept(k, v);
}
@Override public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) { throw new UnsupportedOperationException();
}
@Override public V putIfAbsent(K key, V value) { throw new UnsupportedOperationException();
}
@Override public boolean remove(Object key, Object value) { throw new UnsupportedOperationException();
}
@Override public boolean replace(K key, V oldValue, V newValue) { throw new UnsupportedOperationException();
}
@Override public V replace(K key, V value) { throw new UnsupportedOperationException();
}
@Override public V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) { throw new UnsupportedOperationException();
}
@Override public V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) { throw new UnsupportedOperationException();
}
@Override public V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) { throw new UnsupportedOperationException();
}
@Override public V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) { throw new UnsupportedOperationException();
}
}123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111这个比较简单,比我们自己创建一个 Map 然后把数据放进去简单些。
注意返回的 map 不支持删除、替换操作。
Collections 支持创建单例的其他集合类型:
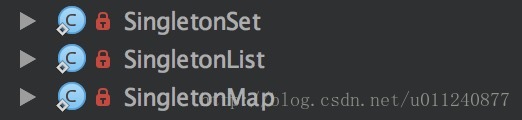
提供的多种集合操作方法
排序
Collections 中提供了按自然排序 Comparable 进行比较的方法 sort(list):
public static <T extends Comparable<? super T>> void sort(List<T> list) { if (list.getClass() == ArrayList.class) { //
Arrays.sort(((ArrayList) list).elementData, 0, list.size()); return;
}
Object[] a = list.toArray();
Arrays.sort(a);
ListIterator<T> i = list.listIterator(); for (int j=0; j<a.length; j++) {
i.next();
i.set((T)a[j]);
}
}1234567891011121314可以看到如果是 ArrayList 就直接调用 Arrays.sort(((ArrayList) list).elementData, 0, list.size()),因为 ArrayList 的底层实现就是数组嘛;否则先调用 Arrays.sort(a),然后遍历、更新。
我们去看一下 Arrays 对数组的排序方法:
public static void sort(Object[] a, int fromIndex, int toIndex) {
rangeCheck(a.length, fromIndex, toIndex); if (LegacyMergeSort.userRequested)
legacyMergeSort(a, fromIndex, toIndex); else
ComparableTimSort.sort(a, fromIndex, toIndex, null, 0, 0);
}static final class LegacyMergeSort { // Android-changed: Never use circular merge sort.
private static final boolean userRequested = false;
}1234567891011通过注释可以看到,Android 中不使用传统的归并排序。那我们看 ComparableTimSort.sort(a, fromIndex, toIndex, null, 0, 0):
static void sort(Object[] a, int lo, int hi, Object[] work, int workBase, int workLen) { assert a != null && lo >= 0 && lo <= hi && hi <= a.length; int nRemaining = hi - lo; if (nRemaining < 2) return; // Arrays of size 0 and 1 are always sorted
// If array is small, do a "mini-TimSort" with no merges
if (nRemaining < MIN_MERGE) { // MIN_MERGE = 32
int initRunLen = countRunAndMakeAscending(a, lo, hi);
binarySort(a, lo, hi, lo + initRunLen); return;
} //... 略去复杂的 TimSort 实现}12345678910111213141516可以看到,如果元素太少,会使用 二分插入排序 binarySort。
binarySort的思想是二分、将后续的数插入之前的已排序数组。
binarySort 对数组 a[lo:hi] 进行排序,并且a[lo:start] 是已经排好序的。
算法的思路是对a[start:hi] 中的元素,每次使用binarySearch 为它在 a[lo:start] 中找到相应位置,并插入。
如果元素太多就会使用 TimSort,这个算法是一种起源于归并排序和插入排序的混合排序算法,由 Tim Peters 于2002 年在 Python 语言中提出。
TimSort 的实现比较复杂,我们这里简单了解一下即可:
TimSort的思想是先对待排序列进行分区,然后再对分区进行合并,看起来和归并排序很相似,但是其中有一些针对反向和大规模数据的优化处理。
Collections 还提供了一种带有定制排序参数的排序方法:
public static <T> void sort(List<T> list, Comparator<? super T> c) { if (list.getClass() == ArrayList.class) {
Arrays.sort(((ArrayList) list).elementData, 0, list.size(), (Comparator) c); return;
}
Object[] a = list.toArray();
Arrays.sort(a, (Comparator)c);
ListIterator<T> i = list.listIterator(); for (int j=0; j<a.length; j++) {
i.next();
i.set((T)a[j]);
}
}1234567891011121314和不传入定制排序比较器使用的算法是一样的,区别就在于比较大小时的标准不一样。
二分查找
我们都知道二分查找需要数据是有序的,在有序的情况下它时间复杂度平均为 O(logn)。
但是在 Collections.binarySearch() 的实现中,针对查找列表的不同类型,采用了不同的查找方法:
public static <T>
int binarySearch(List<? extends Comparable<? super T>> list, T key) { if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD) //BINARYSEARCH_THRESHOLD = 5000;
return Collections.indexedBinarySearch(list, key); else
return Collections.iteratorBinarySearch(list, key);
}12345678如果这个 list 支持随机访问(比如 ArrayList),就调用 indexedBinarySearch() 方法,否则调用 iteratorBinarySearch(),我们挨个看看。
indexedBinarySearch():
private static <T>int indexedBinarySearch(List<? extends Comparable<? super T>> list, T key) { int low = 0; int high = list.size()-1; while (low <= high) { int mid = (low + high) >>> 1; //无符号右移 1 位,等于除二
Comparable<? super T> midVal = list.get(mid); //这个 get 方法时间复杂度为 O(1)
int cmp = midVal.compareTo(key); if (cmp < 0)
low = mid + 1; else if (cmp > 0)
high = mid - 1; else
return mid; // key found
} return -(low + 1); // key not found}12345678910111213141516171819由于支持随机访问,所以在其中的获取方法时间复杂度很低。
相反看下 iteratorBinarySearch 方法:
private static <T>int iteratorBinarySearch(List<? extends Comparable<? super T>> list, T key)
{ int low = 0; int high = list.size()-1;
ListIterator<? extends Comparable<? super T>> i = list.listIterator(); while (low <= high) { int mid = (low + high) >>> 1;
Comparable<? super T> midVal = get(i, mid); //关键在于这个 get)()
int cmp = midVal.compareTo(key); if (cmp < 0)
low = mid + 1; else if (cmp > 0)
high = mid - 1; else
return mid; // key found
} return -(low + 1); // key not found}private static <T> T get(ListIterator<? extends T> i, int index) {
T obj = null; int pos = i.nextIndex(); if (pos <= index) { do {
obj = i.next();
} while (pos++ < index);
} else { do {
obj = i.previous();
} while (--pos > index);
} return obj;
}123456789101112131415161718192021222324252627282930313233343536可以看到,不支持随机访问的 List(比如链表 LinkedList)在二分查找时,每次获取元素都需要去遍历迭代器,这样就大大降低了效率,时间复杂度可能会达到 O(n) 及以上。
反转列表
如果让你实现一个反转列表的方法你会怎么写?据说有的公司出过这样的面试题。
来看看 Collections.reverse(list) 是怎么实现的吧:
public static void reverse(List<?> list) { int size = list.size(); if (size < REVERSE_THRESHOLD || list instanceof RandomAccess) { for (int i=0, mid=size>>1, j=size-1; i<mid; i++, j--)
swap(list, i, j);
} else { // instead of using a raw type here, it's possible to capture
// the wildcard but it will require a call to a supplementary
// private method
ListIterator fwd = list.listIterator();
ListIterator rev = list.listIterator(size); for (int i=0, mid=list.size()>>1; i<mid; i++) {
Object tmp = fwd.next();
fwd.set(rev.previous());
rev.set(tmp);
}
}
}public static void swap(List<?> list, int i, int j) {
final List l = list;
l.set(i, l.set(j, l.get(i)));
}12345678910111213141516171819202122可以看到,当 List 支持随机访问时,可以直接从头开始,第一个元素和最后一个元素交换位置,一直交换到中间位置。
这里的这个 swap() 交换方法写的很简练哈,这里简单解释一下:
l.get(i)返回位置 i 上的元素l.set(j,l.get(i))将 i 上的元素设置给 j,同时由于List.set(i,E)返回这个位置上之前的元素,所以可以返回原来在 j 上的元素然后再设置给 i
我们需要对集合的方法很熟悉才能写出这样的代码。
话说回不支持随机访问的列表,就使用两个迭代器,一个从头开始一个从尾开始,遍历、赋值。
还是比较简单的哈。
打乱列表中的元素
这个应该很容易实现的,只要随机交换元素的位置就好了。看看是不是这么实现的呢:
public static void shuffle(List<?> list) {
Random rnd = r; if (rnd == null)
r = rnd = new Random(); // harmless race.
shuffle(list, rnd);
}public static void shuffle(List<?> list, Random rnd) { int size = list.size(); if (size < SHUFFLE_THRESHOLD || list instanceof RandomAccess) { for (int i=size; i>1; i--) //支持随机访问,就随机赋值
swap(list, i-1, rnd.nextInt(i));
} else {
Object arr[] = list.toArray(); //不支持随机访问,就转成数组
// Shuffle array
for (int i=size; i>1; i--) //然后遍历数组交换
swap(arr, i-1, rnd.nextInt(i));
ListIterator it = list.listIterator(); for (int i=0; i<arr.length; i++) { //把打乱的元素写回列表
it.next();
it.set(arr[i]);
}
}
}12345678910111213141516171819202122232425可以看到,在打乱列表时能否随机访问的列表使用的方式也略有不同。支持随机访问的就直接随机交换即可。
不支持随机访问的,在这种需要对全部元素做操作的情况下就比较尴尬了。上面的代码先将列表转成了数组,我们看看不支持随机访问的典型代表 LinkedList 如何实现的 toArray() 方法:
public Object[] toArray() { Object[] result = new Object[size]; int i = 0; for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item; return result;
}1234567辛酸泪啊,得遍历一次。
转成数组后先进行了随机交换,然后又把打乱的元素写回列表,折腾死了哦。
填充列表
Collections 还有个 fill() 方法,表示使用指定的元素替换列表中的所有元素,也就是“你们都滚蛋,让我复制 N 个”。
public static <T> void fill(List<? super T> list, T obj) { int size = list.size(); if (size < FILL_THRESHOLD || list instanceof RandomAccess) { for (int i=0; i<size; i++) list.set(i, obj);
} else {
ListIterator<? super T> itr = list.listIterator(); for (int i=0; i<size; i++) {
itr.next();
itr.set(obj);
}
}
}1234567891011121314实现很简单,介绍它是因为好奇什么时候会有这个需求?
求出集合中最小/大值
求最大最小值很简单,这里就不说了,就是提醒大家 Collections 有这些个方法:
public static <T extends Object & Comparable<? super T>> T min(Collection<? extends T> coll) {
Iterator<? extends T> i = coll.iterator(); T candidate = i.next(); while (i.hasNext()) { T next = i.next(); if (next.compareTo(candidate) < 0)
candidate = next;
} return candidate;
}
public static <T> T max(Collection<? extends T> coll, Comparator<? super T> comp) { if (comp==null) return (T)max((Collection) coll);
Iterator<? extends T> i = coll.iterator(); T candidate = i.next(); while (i.hasNext()) { T next = i.next(); if (comp.compare(next, candidate) > 0)
candidate = next;
} return candidate;
}12345678910111213141516171819202122232425查找子列表最早出现的索引
又是一道典型的面试题,你会怎么解呢?
我们来看看 Collections 类给出的方法吧:
public static int indexOfSubList(List<?> source, List<?> target) { int sourceSize = source.size(); int targetSize = target.size(); int maxCandidate = sourceSize - targetSize; //记录父列表和子列表个数差距
if (sourceSize < INDEXOFSUBLIST_THRESHOLD ||
(source instanceof RandomAccess&&target instanceof RandomAccess)) { //支持随机访问
nextCand: //定义跳转入口
for (int candidate = 0; candidate <= maxCandidate; candidate++) { //从0开始
for (int i=0, j=candidate; i<targetSize; i++, j++) if (!eq(target.get(i), source.get(j))) continue nextCand; // Element mismatch, try next cand
return candidate; // All elements of candidate matched target
}1234567891011121314先看支持随机访问的(比如 ArrayList)。
这里的代码使用了暴力的双重循环,第一层从 0 开始,最多查找 maxCandidate(父列表和子列表个数差距)次;
第二层开始,将第一层遍历的索引范围内,父列表和子列表对应位置的元素挨个对比,一旦有一个不相等,就回到第一层循环,继续往后走一个。
直到第二层顺利循环结束,就找到了子列表的索引。
其实思想就是:用两个游标,一个表示父列表的第一个元素,另一个表示可能是子列表元素范围的索引,在遍历过程中如果发现的确和子列表所有元素都相等,那就找到了子列表。
话说回来不支持随机访问的是如何找到子列表的呢?
} else { // Iterator version of above algorithm
ListIterator<?> si = source.listIterator();
nextCand: for (int candidate = 0; candidate <= maxCandidate; candidate++) {
ListIterator<?> ti = target.listIterator(); for (int i=0; i<targetSize; i++) { if (!eq(ti.next(), si.next())) { // Back up source iterator to next candidate for (int j=0; j<i; j++)
si.previous(); continue nextCand;
}
} return candidate;
}
} return -1; // No candidate matched the target
}123456789101112131415161718思想有些类似,不同的是在不相等时,会往前移动一位指示目标列表位置的索引。
总结
可以看到 Collections 方法提供了很多有用的工具方法,其中有一部分也涉及到一些算法,经过这篇文章你是不是更了解了呢?
Thanks
http://blog.csdn.net/bruce_6/article/details/38299199
更多精彩分享
- 游戏论坛项目感言 2023-04-08 10:31:50.253
- 游戏论坛模拟 2023-04-08 10:45:38.443
- 云笔记 2022-07-13 15:06:14.387
- Shopify Experts 2022-02-21 23:44:46.197
- Google Ads Specialist 2022-01-04 20:00:59.0
- Buy here pay here PA 2021-08-31 19:11:51.327
- 萨达萨达所大所大所多 2019-04-04 12:34:03.7
- 5G时代,会是国产操作系统突破的契机吗? 2018-12-26 23:31:29.32
- 8年时间,什么叫从0到1?雷军的小米已注定成传奇! 2018-12-26 23:10:40.077
- Top Mobile Development Company in India 2018-08-16 21:18:29.953
 游戏论坛模拟
游戏论坛模拟