机器学习
Gssol
20170620 星期二
1 机器学习概念
机器学习,通常的机器指的是“计算机”,机器学习就是让计算机自己学习。最主要的思想是“统计”和“分类”。
通常的是给计算机一些指令,然后计算机进行处理;而机器学习主要是分析数据,产生模型,进而进行预测。
“等人事件”: 例如和某人有约,但不知道对方到达时间我们可以根据对方平时的到达情况来判断自己什么出门等待的时间最少。我们是根据之前的情况来进行分析,利用机器学习,让计算机自己统计之前的数据进行分析,从而对本次情况进行预测。可以利用决策树来处理等人问题。当然天气、堵车情况也会对结果造成影响,暂不考虑。
“分类事件”:对垃圾邮件进行分类,找出某种鸟(对鸟类进行分类)
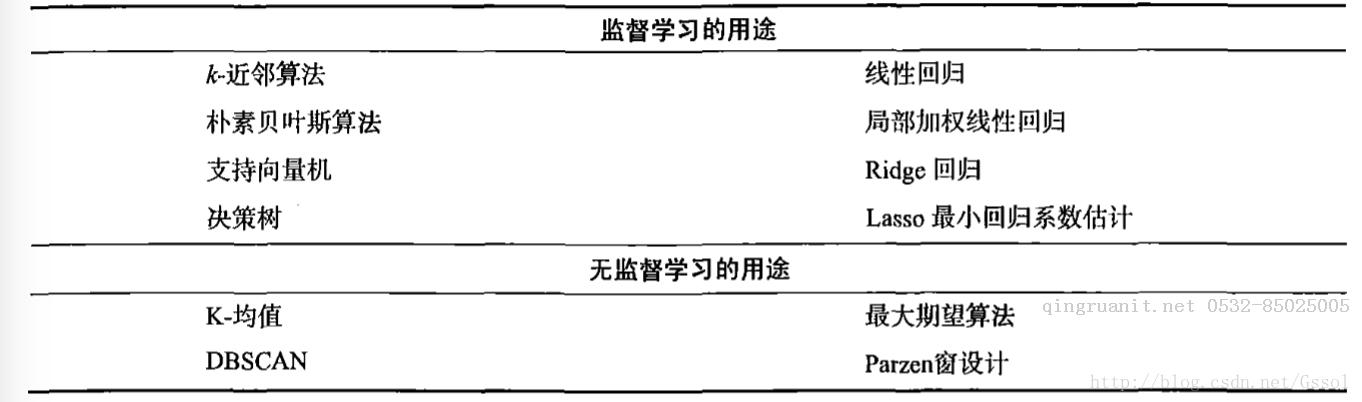
2 监督学习与无监督学习
监督学习:必须知道预测什么,即目标变量的分类信息。需要将实例数据划分到合适的分类中,然后进行回归,产生曲线,进而预测数据。
无监督学习:数据没有类别信息,也不会给定目标值。将数据集合分成由类似的对象组成的多个类的过程称为聚类,将寻找描述数据统计值的过程称为密度估计,还可以减少数据特征的维度,更加直观地显示数据信息。
3 k-近邻算法
k-近邻算法
Pros:精度高、对异常值不敏感、无数据输入设定
Cons:计算复杂度高、空间复杂度高
Works with:数值型和标称型
3.1 电影题材分类问题
判断一部未知电影是爱情片还是战争片,我们可以统计接吻次数和打斗次数来进行判断。
下面是六部电影的统计情况,?位需要判断的电影。
可以通过计算未知电影与已知的六部电影之间的距离,然后找出距离最小的前k位(通常k<20),再进行
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式