Learning to Rank是采用机器学习算法,通过训练模型来解决排序问题,在Information Retrieval,Natural Language Processing,Data Mining等领域有着很多应用。
1. 排序问题
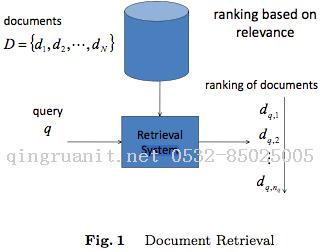
如图 Fig.1 所示,在信息检索中,给定一个query,搜索引擎会召回一系列相关的Documents(通过term匹配,keyword匹配,或者semantic匹配的方法),然后便需要对这些召回的Documents进行排序,最后将Top N的Documents输出。而排序问题就是使用一个模型 f(q,d)来对该query下的documents进行排序,这个模型可以是人工设定一些参数的模型,也可以是用机器学习算法自动训练出来的模型。现在第二种方法越来越流行,尤其在Web Search领域,因为在Web Search 中,有很多信息可以用来确定query-doc pair的相关性,而另一方面,由于大量的搜索日志的存在,可以将用户的点击行为日志作为training data,使得通过机器学习自动得到排序模型成为可能。
需要注意的是,排序问题最关注的是各个Documents之间的相对顺序关系,而不是各个Documents的预测分最准确。
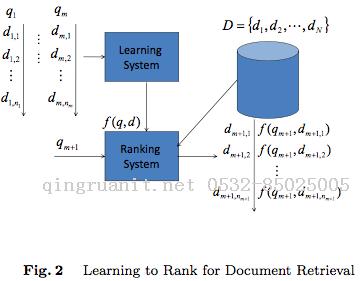
Learning to Rank是监督学习方法,所以会分为training阶段和testing阶段,如图 Fig.2 所示。