1 什么是机器学习
什么是机器学习?
这个问题不同的人员会有不同的理解。我个人觉得,用大白话来描述机器学习,就是让计算机能够通过一定方式的学习和训练,选择合适的模型,在遇到新输入的数据时,可以找出有用的信息,并预测潜在的需求。最终反映的结果就是,好像计算机或者其他设备跟人类一样具有智能化的特征,能够快速识别和选择有用的信息。
机器学习通常可以分为三个大的步骤,即 输入、整合、输出,可以用下图来表示大致的意思:
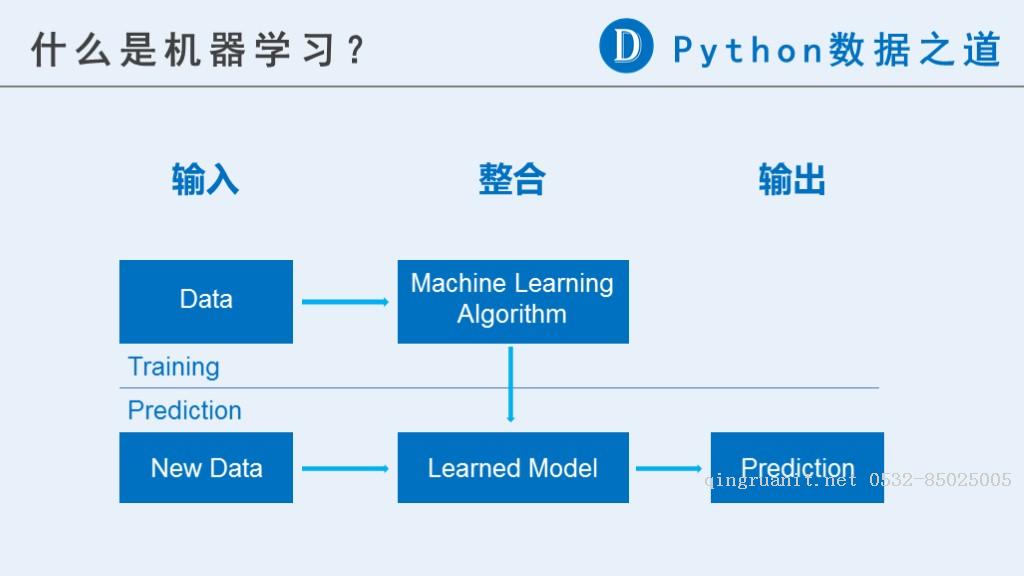
2 机器学习示例(scikit-learn)
在python语言中,scikit-learn是一个开源的机器学习库。下面以sklearn为例,来简单描述机器学习的过程。
2.1 加载数据
通常第一步是获取相关数据,并进行相应的处理,使之可以在后续过程中使用。
from sklearn import datasets
加载iris数据集并查看相关信息
# 加载数据集iris = datasets.load_iris()# print(iris)print(type(iris)) print(iris.keys())# 查看部分数据print(iris.data[ :5, :])# print(iris.data)
<class 'sklearn.datasets.base.Bunch'>
dict_keys(['DESCR', 'data', 'feature_names', 'target', 'target_names'])
[[ 5.1 3.5 1.4 &nb
延伸阅读
- ssh框架
2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁
2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe
2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】
2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词
2017-07-26
- 从栈不平衡问题 理解 calling convention
2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明
2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解
2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析
2017-07-26
- 集合结合数据结构来看看(二)
2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式