这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解
该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider/tree/master/jobboleSpider
注:这个文章并不会对详细的用法进行讲解,是为了让对scrapy各个功能有个了解,建立整体的印象。
在学习Scrapy框架之前,我们先通过一个实际的爬虫例子来理解,后面我们会对每个功能进行详细的理解。
这里的例子是爬取http://blog.jobbole.com/all-posts/ 伯乐在线的全部文章数据
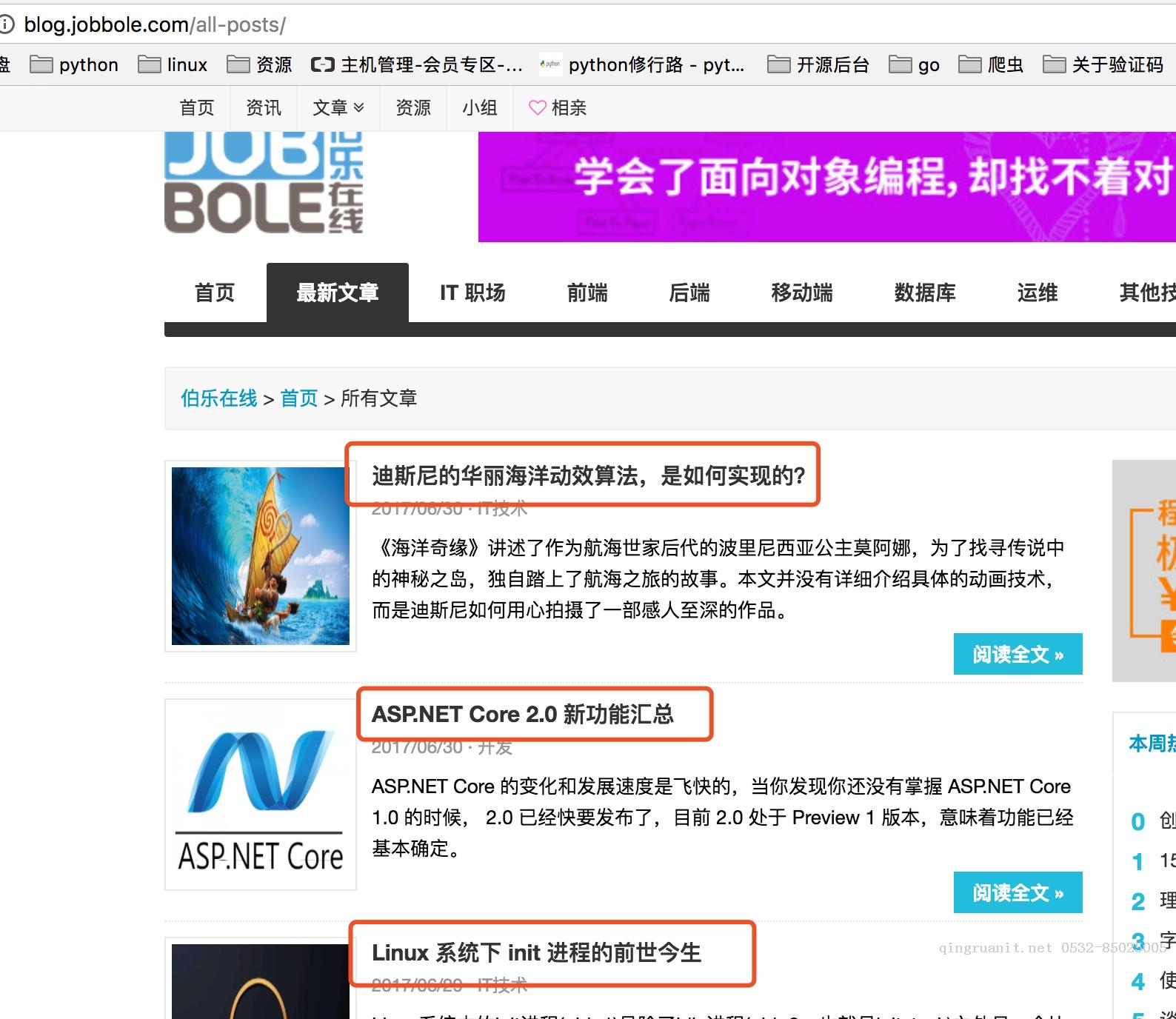
分析要爬去的目标站信息
先看如下图,首先我们要获取下图中所有文章的连接,然后是进入每个文章连接爬取每个文章的详细内容。
每个文章中需要爬取文章标题,发表日期,以及标签,赞赏收藏,评论数,文章内容。