在浏览器客户端进行爬虫开发
JS是个神奇的语言,借助Node.js的后端环境,我们可以进行相应的爬虫开发,如这篇 基于Node.js实现一个小小的爬虫
但搭建后台环境始终略为麻烦,拿到一台新电脑,不用配环境,可不可以直接在浏览器客户端直接实现呢?
可以可以,这里就简单地说一下在浏览器客户端实现的爬虫抓取页面数据
一、概念理解
爬虫,简单地说就是发一个请求,然后按一定逻辑解析获取到的数据。
在Node环境下,可以用Request模块请求一个地址,得到返回信息,再用正则匹配数据,或者用Cheerio模块包装-方便定位相关的标签项
在浏览器环境下,也类似,可以用标签的src属性或Ajax请求一个地址,得到返回信息,再用正则匹配数据,或者用jQuery模块包装-方便定位相关的标签项
二、实现
实现的本质都是打开浏览器的开发者工具,写一段JS代码注入到页面中,然后让相关代码自执行地址请求,再通过代码处理返回的数据
打开Chrome浏览器的开发者工具,选择面板中的 sources 部分,选择二级菜单的 script snippets 部分,然后右键新建一个脚本,在右方输入想注入的代码
然后右键script snippets脚本运行(或者使用快捷键 Ctrl + Enter 运行)就可以开始注入,并可以在下方 console 部分看到相应的结果
注入JS代码的方式是使用一个script标签,定义src指向的脚本地址,或者在标签中直接定义JS代码
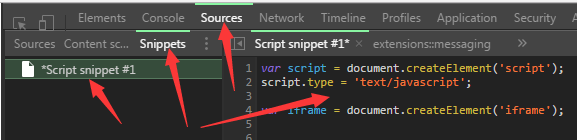
在浏览器端的爬虫实现,这里分为两个方面:一个是处理纯页面的请求,一个是处理Ajax的异步请求
延伸阅读
- ssh框架
2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁
2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe
2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】
2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词
2017-07-26
- 从栈不平衡问题 理解 calling convention
2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明
2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解
2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析
2017-07-26
- 集合结合数据结构来看看(二)
2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
学习是年轻人改变自己的最好方式