一家"胡说八道医院"拥有一种治疗癌症的药物, 根据过去的记录, 该药物对一些患者非常有效, 但是会让一些患者感到更痛苦...
我们希望有一种判别准则能帮助我们判断哪些病人该吃药,哪些不能吃药.研究发现该癌症与基因表达有关,也许基因表达能给我们提供帮助...
首先使用一个基因判别

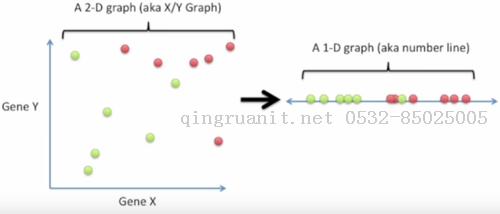
把所有病人的基因X转录水平画在数轴上, 用绿点表示服用药物有效的病人, 红点表示服用药物后更痛苦的病人.
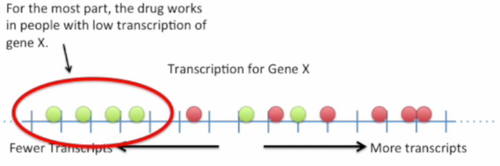
我们可以看到服用药物有效的大部分患者的基因X转录水平都较低
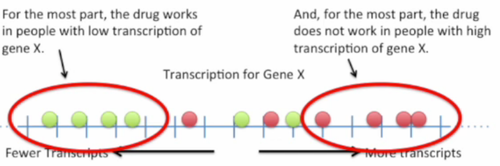
服用药物无效的大部分患者的基因X转录水平都较高
但在中间, 我们发现红点和绿点是有交叉的, 所以如果只使用基因X来判别只能获得"还可以"的分类效果.那么使用更多的基因来判断会不会有更好的效果呢?
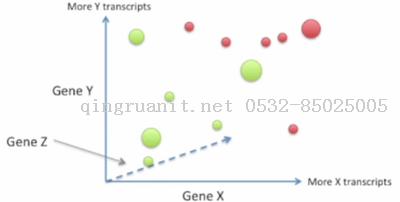
使用两个基因判别

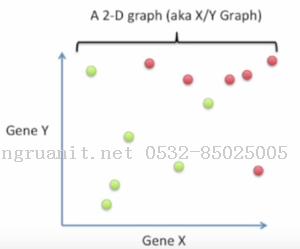
这次我们使用基因X和基因Y来判别.以基因X的转录水平作为横坐标, 基因Y的转录水平作为纵坐标, 绿点代表药物有效的患者, 红点代表药物无效的患者.
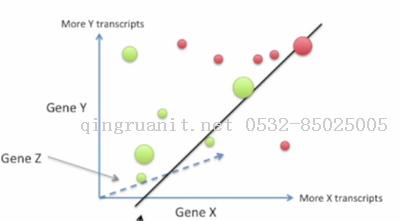
直观来看, 我们可以使用一条直线来划分这两类患者.
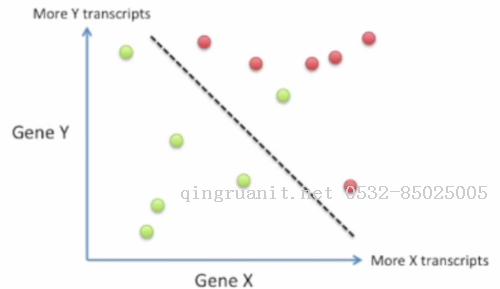
直线左下方的判断为"应该吃药"的患者, 右上方的判断为"不应该吃药"的患者. 我们可以看到使用两个基因来判断要比单个基因更为准确, 然而这还不够完美.那么使用三个基因会获得更好的结果吗?
使用三个基因判别

这次我们加入了基因Z, 以基因Z表示虚线那条坐标.虽然有点丑, 但这个图是一个三维图(请发挥你的想象力), 比较大的点是离我们比较近的点, 比较小的点则离得较远.
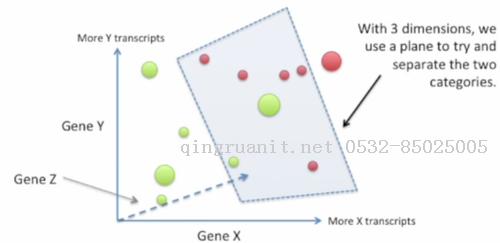
在这个三维空间中, 我们可以使用一个平面来划分这两类点. 但是从这个角度很难看出我们有没有完美地划分开两类点, 这需要换个角度看看, 但我们就偷偷懒不画换了角度的图了.
那么如果我们使用四个基因来区分两类点会怎样呢?
使用四个或更多基因
对于四个或更多的基因, 我们就没办法画出图像了= =
我们知道基因是非常多的, 大部分时候我们都画不出图像来, 如果可以把维数很大的数据压缩成我们可以画出来的三维以内的数据就好了.
这时候线性判别分析(Linear Discriminant Analysis,LDA)就可以出场了.
可能你已经知道了主成分分析(Principal Component Analysis,PCA)也可以做这样的事情.那么他们之间有什么联系和区别呢?
都是通过重要性对新生成的坐标进行排序
PC1(第一主成分)捕捉了数据中的最大变化
LD1(LDA产生的第一坐标)捕捉了不同类别中最大的差异
LDA和PCA都可以用于降低维数, 这对于在平面上画出有许多维数(许多基因)的数据来说非常有帮助. 此外, 对于一些与距离相关的算法, 比如K-Means, 如果维数太高了会影响最终效果的; 对于一些分类算法, 降低维度对后续的分类效果也是有帮助的.
PCA降低维度时是保留数据中大部分的"变化"
LCA降低维度时是尽可能保留不同类别间的"区分度"
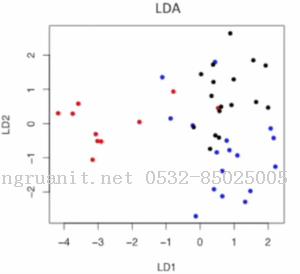
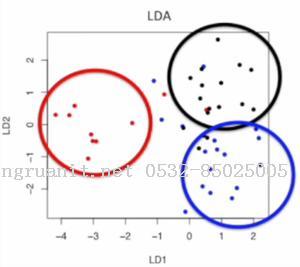
这是使用LDA把数据降至2维的图, 我们可以发现可以发现降维后, 这三类点还是比较容易区分的
同样的任务, 如果使用PCA, 结果是这样的, 我们会发现蓝点跟黑点几乎混杂在一起了
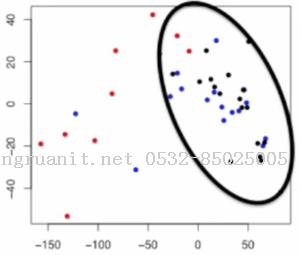
对比之下, LDA比PCA更利于后续的分类任务
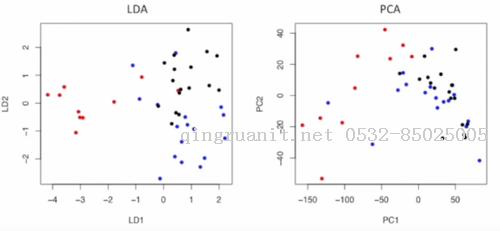
总而言之, 线性判别分析跟主成分分析很像, 但是它想做的是最大化类别间区分度的条件下降低维度.
一个简单的例子
比如我们希望把这样的二维数据点(平面上的点)变成一维数据点(直线上的点)
怎样的映射方式最好呢?即能最大程度地保留类别间的区分度呢?为了明白怎样是好的, 我们先来看看什么是不好的.
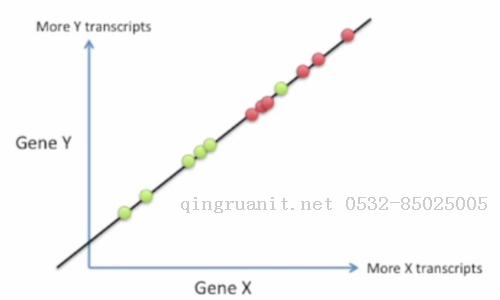
其中一种不好的映射就是把所有点都投影到X轴上

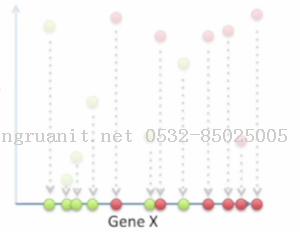
如果这么映射, 相当于我们只使用了基因X的信息, 而完全无视基因Y的信息, 这样会丢失许多有利于区分两类点的信息, 所以是一种不好的映射.
LDA则给出了一种更好的映射方式.LDA利用两个基因的信息产生一个新的坐标(直线)
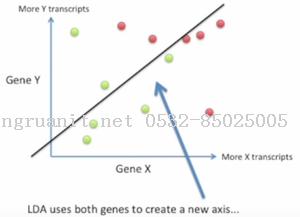
然后把数据点都往这个坐标上投影, 生成的新坐标可以醉城成都地保留类别间的区分度
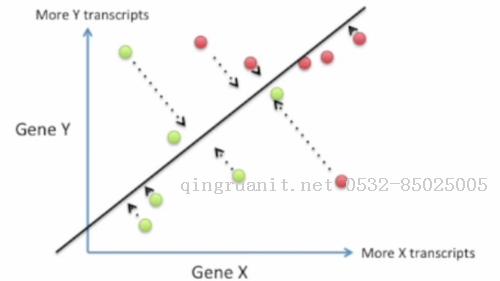
那么LDA是怎么生成这个新坐标的呢?
LDA怎么生成新坐标
我们希望尽可能地保留"区分度", 一种比较简单的想法就是希望在这两类点中找出两个代表点, 使得这两个代表点映射到新坐标上后离得越远越好
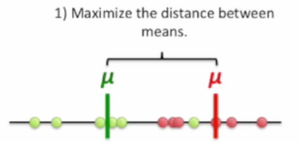
这里我们可以使用数据点的均值来作为代表点.
但是如果同一类的点本身就散得很开(不是集中在代表点附近), 那就算代表点离得很远, 也很难保证我们轻易地在新坐标上区分两类点. 所以还得要求同一类内的点不要太过于分散.
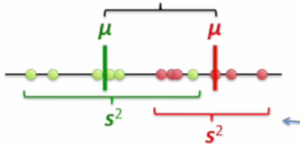
绿色的s2代表旅绿分散程度, 红色的s2代表红点的分散程度.
对于上面的两条准则, 我们希望代表点在新坐标上离得越远越好(即距离越大越好), 类内的分散程度越小越好. 如果想把这两个要求整合在一起, 一个直接的方法是使用分式.
把越大越好的项放在分子, 越小越好的项放在分母
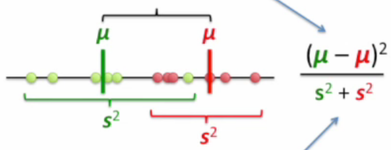
这样,我们只需要以这个分式越大越好的原则去寻找新的坐标就好了.
为什么距离和分散程度都很重要呢?

如果我们只要求代表点映射在新坐标上后距离越远越好, 不要求分散程度尽可能小, 则对于上面这两类点, 可能会得到绿线这样的一个新坐标, 在下方的直方图中, 我们可以看到这样投影到直线上后, 其实两类点之间是有很多重叠的, 这样的效果不能令我们满意

若在考虑距离的同时还要求映射后类内的分散程度尽可能小, 则会得到这样的一个新坐标, 在左下角的直方图中我们可以看到这次的两类点投影到新坐标后几乎没有重叠的部分.
所以距离和分散程度准则都很重要!
更高维数的LDA
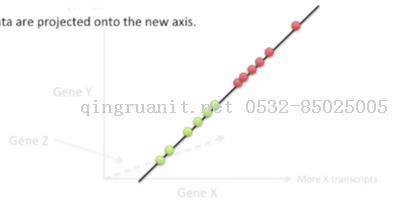
对于更高的维数, 比如说三维, LDA的工作方式和二维是差不多的, 以刚刚展示过的三维图为例
首先, 我们还是生成一条新坐标, 然后把数据点都映射到这条坐标轴上, 这条坐标轴也是根据距离和分散程度两个准则找出来的
更多类别的LDA
更高维数的情况与最简单的情况没太大区别, 而更多类别的情况则稍有不同,比如有三类数据点(比如患者对这款药的反应有"有效", "没反应", "痛苦")
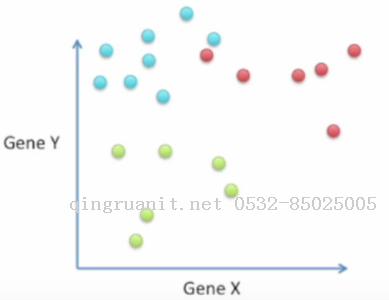
有两个地方与之前的情形不太一样
均值间距离的度量方式
首先我们找到所有数据的均值点(黑点)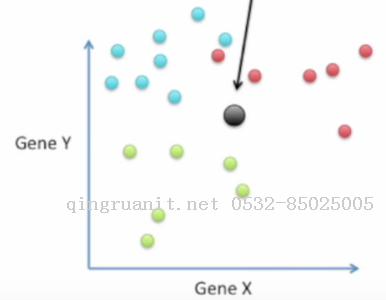
然后分别找到相同类数据的均值点(蓝点, 红点, 绿点)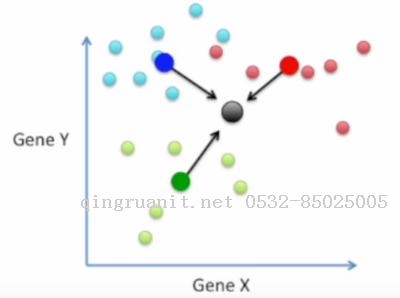
计算各类均值点与所有数据均值点的距离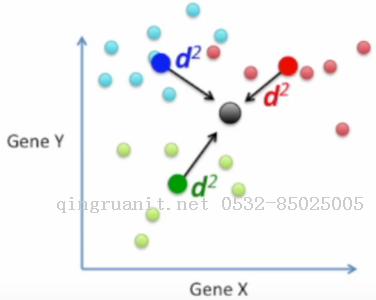
我们希望最大化各类均值点与黑点之间的距离, 同时最小化各类之间的分散程度.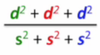
与之前相比公式中多了蓝色的这两项
第二个不同是LDA会生成两个坐标来划分数据
这是因为两点确定一条直线而三点确定一个平面(蓝点, 红点, 绿点). 在这里我们相当于重新选择了X轴和Y轴
在二维的情况下, 我们只是把XY平面中的点在另外一个XY平面上重新画出来, 这好像没什么了不起.
但是如果数据点有10000维的话...在XY平面上重新画出这些点就比较酷了!
在前文中比较LDA和PCA时的那幅图便是把1000维数据点降到2维平面显示出来的效果.
虽然降维程度这么大, 我们依然能轻松地分辨三类数据点, 而PCA在这点上则做得不这么令人满意了, 它只是尽可能地捕捉数据中的最大方差, 无需用到类别信息(所以是无监督的方法), 而LDA需要用到类别信息(有监督方法)
LDA的Python实现
#!/usr/bin/env python# encoding: utf-8from __future__ import divisionimport numpy as npfrom numpy.linalg import pinvimport timedef FDA_train(X_1, X_2): """Fisher's Discriminant Analysis training The FDA_train calculates the project direction w* and classification thredshold w_0 of FDA model. Parameters ---------- X_1 : array-like, shape(n_samples, n_features) Training data of class 1 X_2 : array-like, shape(n_samples, n_features) Training data of class 2 Returns ------- w_star : array-like, shape(n_features, ) The best project direction w* under the Fisher's criterion w_0 : float The classification thredshold based on w_0 = -(1/2)(m_1_tilde + m_2_tilde) """ n_1,d_1 = np.shape(X_1) n_2, d_2 = np.shape(X_2) m_1 = np.mean(X_1, axis = 0) m_2 = np.mean(X_2, axis = 0) M_1 = np.array([m_1,]*n_1) M_2 = np.array([m_2,]*n_2) S_1 = ((X_1 - M_1).T).dot(X_1 - M_1) S_2 = ((X_2 - M_2).T).dot(X_2 - M_2) S_w = S_1 + S_2 #Calculating the best project direction w^* w_star = pinv(S_w).dot((m_1 - m_2).T) y_1 = X_1.dot(w_star) y_2 = X_2.dot(w_star) m_1_tilde = y_1.sum() / n_1 m_2_tilde = y_2.sum() / n_2 #Calculating the thredshold w_0 w_0 = -(m_1_tilde + m_2_tilde) / 2 return w_star, w_0def FDA_test(X_test, w_star, w_0): """Fisher Discriminant Analysis test The FDA_test projects the data points stored in X_test to the direction presented by w_star and compare the value y on the new axis with the specified threshold w_0, if y >= w_0 then the data point is classified into class 1, else class 2 Parameters ---------- X_test : array-like, shape(n_samples, n_features) The testing data w_star : array-like, shape(n_features, ) The best project direction w* under the Fisher's criterion w_0 : float The classification thredshold based on w_0 = -(1/2)(m_1_tilde + m_2_tilde) Returns ------- y_pred: array-like, shape(n_samples,k_classes) y_pred contains the class labels of each sample represented by 1-of-K format.(one hot encode) """ y_proj = X_test.dot(w_star)[:, np.newaxis] #1-of-K code scheme y_1 = y_proj >= w_0 y_2 = y_proj < w_0 y_pred = np.hstack((y_1, y_2)).astype(int) return y_pred
参考资料
1.https://www.youtube.com/watch?v=azXCzI57Yfc
2.https://en.wikipedia.org/wiki/Linear_discriminant_analysis
3.Bishop C. Pattern Recognition and Machine Learning ,2006
http://www.cnblogs.com/bayesianML/p/6397911.html
延伸阅读
- 告别“老顽固” 2023-04-18 11:15:46.437
- 时光飞逝 2024-03-26 11:25:53.823
- 会当凌绝顶,一览众山小 2023-04-18 10:38:34.08
- 自豪 2023-04-18 10:31:27.963
- 绽放 2023-04-18 10:30:19.243
- 毕业有感 2023-04-18 10:27:54.643
- 投入六个月的经历,收获了整个人生 2023-04-18 10:18:55.813
- 非常响亮的名字 2023-04-18 10:10:46.923
- 不可磨灭的力量 2023-04-18 10:06:02.717
- 困难是把双刃剑 2023-04-18 10:04:30.883
 告别“老顽固”
告别“老顽固”