Linux系统中文语言乱码,是很多小伙伴在开始接触Linux时经常遇到的问题,而且当我们将已在Wndows部署好的项目搬到Linux上运行时,Tomcat的输出日志中文全为乱码(在Windows上正常),看着非常心塞,那么我们应该怎么解决呢?

系统中文乱码

Tomcat输出日志中文乱码
系统环境
CentOS 7.0 64位
jdk-8u11-linux-x64.
apache-tomcat-8.5.16
解决步骤:
1.安装中文语言包
先查看系统是否有安装中文语言包
# locale -a (列出所有可用的公共语言环境的名称)
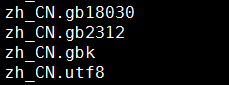
若发现以上几项,说明系统已安装中文语言包,无需再安装,那这几项代表什么意思呢?
{语言代号}_{国家代号}.{字符集}
zh是中文的代号、CN是中国的代号、gb18030,gb2312,utf8是语言字符集
那么每一项可以通俗理解为 “你是说中文的,你在中国,语言字符集是gb18030/gb2312/utf8”
如果没有发现以上几项,则手动安装中文语言包
# yum install kde-l10n-Chinese (大概11M)
2.修改i18n国际化和locale.conf本土化配置文件
在修改配置文件之前,我们先看看当前系统语言环境
# locale

("en_US.UTF-8"按照上面的内容可以理解为“你说英语,你在美国,语言字符集为UTF-8”)
每项的意思分别为 :
LANG:当前系统的语言
LC_CTYPE:语言符号及其分类
LC_NUMERIC:数字
LC_COLLATE:比较和排序习惯
LC_TIME:时间显示格式
LC_MONETARY:货币单位
LC_MESSAGES:信息主要是提示信息,错误信息, 状态信息, 标题, 标签, 按钮和菜单等
LC_NAME:姓名书写方式
LC_ADDRESS:地址书写方式
LC_TELEPHONE:电话号码书写方式
LC_MEASUREMENT:度量衡表达方式
LC_PAPER:默认纸张尺寸大小
LC_IDENTIFICATION:对locale自身包含信息的概述
LC_ALL:优先级最高变量,若设置了此变量,所有LC_* 和LANG变量会强制跟随它的值
我们看到虽然安装了中文语言包但本机的语言环境并不是中文,先修改i18n配置文件
# vim /etc/sysconfig/i18n
添加如下两行代码
LANG="zh_CN.UTF-8"
LC_ALL="zh_CN.UTF-8"

# source /etc/sysconfig/i18n
再修改 locale.cnf配置文件
# vim /etc/locale.conf
LANG="zh_CN.UTF-8"

# source /etc/locale.conf
重启系统
# reboot
3.设置终端连接编码
文件->打开->选中会话->右键->属性->终端 (我用的终端连接工具是Xshell,其它连接工具更改编码方式请自行百度)
将编码改为 UTF-8
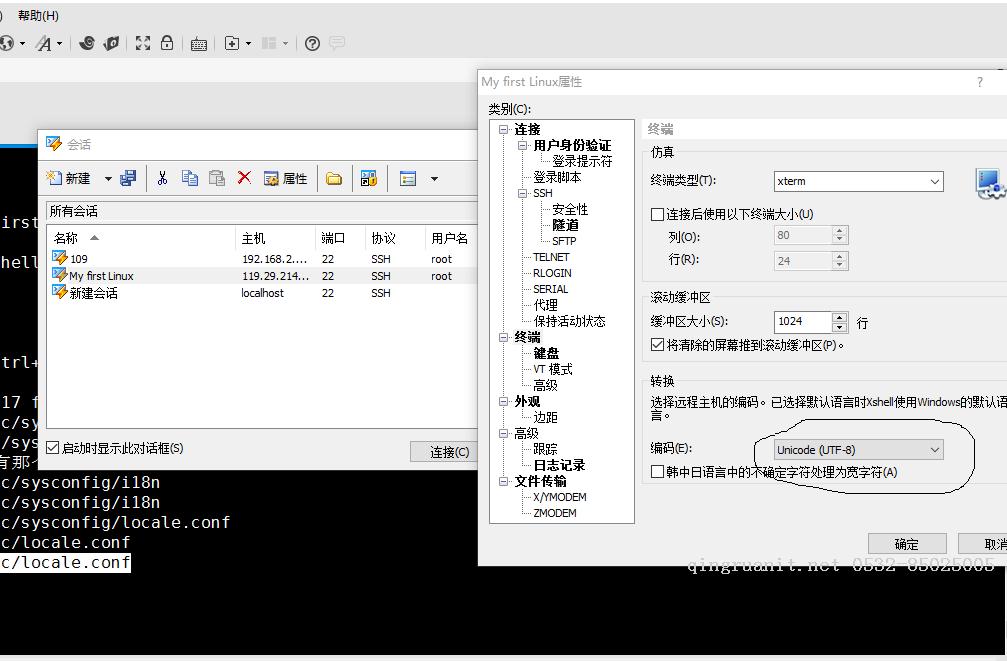
重新连接,再查看当前系统语言环境
# locale
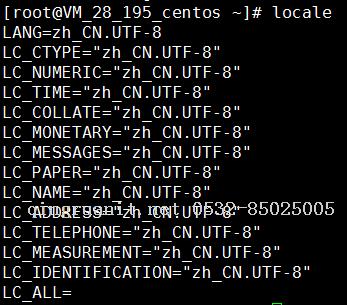
发现系统语言环境已经成功改为 “zh_CN.UTF-8”
再次尝试编辑中文
# vim 你是猪吗

# ls

SUCCESS!至此,系统中文乱码问题已解决。
4.解决Tomcat输出日志乱码
既然系统中文乱码已经解决了,那么Tomcat输出日志中文乱码会不会也解决了呢?
我们现在看看Tomcat输出日志
进入Tomcat目录
# cd $CATALINA_HOME
# tail -f ./logs/catalina.out

很遗憾,Tomcat日志中文还是乱码。
分析:既然系统已经不会出现中文乱码,证明系统语言环境是正常的,但是Tomcat日志还会出现中文乱码,说明是Tomcat内部的问题,网上查了一些资料,知道是JVM(Java Virtual Machine)
java虚拟机所用的字符集与系统所用的字符集不一致造成的,知道原因,问题就好解决了,可以通过配置JVM的启动参数来达到修改JVM所使用字符集的目的。
# ls -l ./bin/

找到 daemon.sh 和 catalina.sh 分别加入以下代码:
JAVA_OPTS="$JAVA_OPTS -Djavax.servlet.request.encoding=UTF-8 -Dfile.encoding=UTF-8 -Duser.language=zh_CN -Dsun.jnu.encoding=UTF-8"
# vim ./bin/daemon.sh

# vim ./bin/catalina.sh

保存退出,重启Tomcat
# ./bin/shutdown.sh
# ./bin/startup.sh
现在再查看输出日志
# tail -f ./logs/catalina.out
向服务器发一次请求

Tomcat输出日志中文正常显示。
end! (*^-^*)
-----------------------------------------------本人能力有限,有错误或者不足之处欢迎指正,也欢迎联系我交流学习------------------------------------------------------------
联系方式
电子邮箱:1424769309@qq.com
微信号:R1284103044
http://www.cnblogs.com/admix/p/7145200.html
延伸阅读
- 有问题就会有答案 2023-04-15 14:14:16.593
- 黑暗四剑客日志——刘*行 2019-04-13 14:21:56.92
- 为解决困难而存在 2019-03-13 16:26:59.81
- 没有什么不是一个好的团队不可以解决的—由*潮 2017-10-27 14:41:00.813
- 站在客户的角度上思考问题——王*大维 2017-08-28 16:51:53.797
- 从栈不平衡问题 理解 calling convention 2017-07-26 16:43:56.853
- 通过history解决ajax不支持前进/后退/刷新 2017-07-26 16:22:48.437
- Go语言学习笔记(四)结构体struct & 接口Interface & 反射 2017-07-26 14:12:45.07
- 官方Tomcat镜像Dockerfile分析及镜像使用 2017-07-25 17:03:33.857
- Vue 实际项目中你可能会遇见问题 2017-07-25 16:45:19.947
 有问题就会有答案
有问题就会有答案